
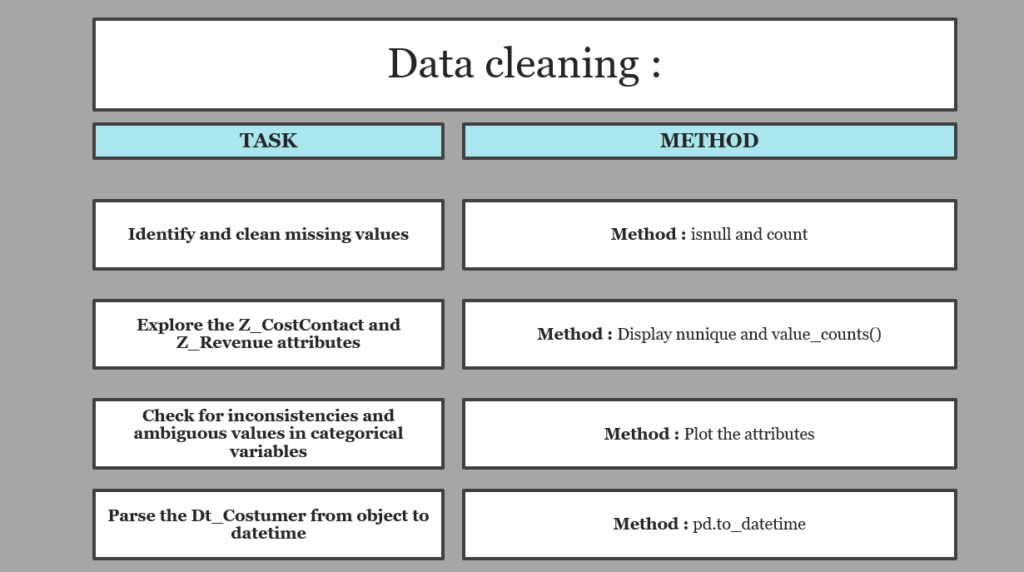
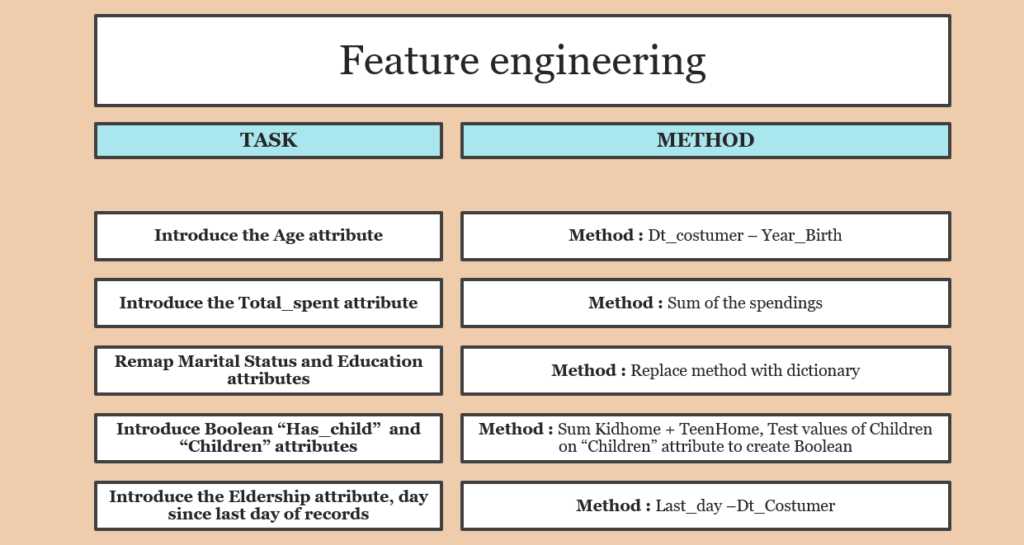
I generally like to plot a correlation heat map to see the linear relationship between variables :
- It gives us an idea what PCA is going to use for dimensional reduction


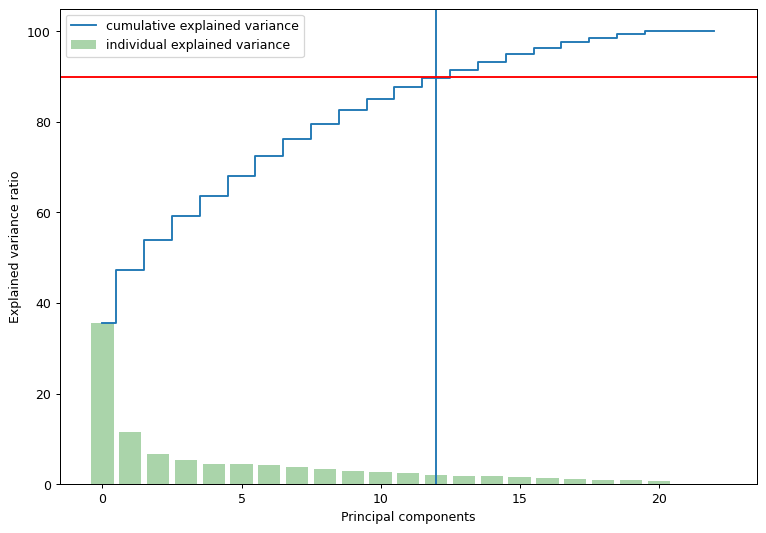
Once the dust has settled and you finally have your cumulative variance, you can assess the dimensional reduction
From the plot above, it can be seen that approximately 90% of the variance can be explained with the 14 principal components. Therefore for the purposes of this notebook, let’s implement PCA with 13 components

Now that I have reduced the attributes to three dimensions, I will be performing clustering via Agglomerative clustering. Agglomerative clustering is a hierarchical clustering method. It involves merging examples until the desired number of clusters is achieved.
Steps involved in the Clustering
- Elbow Method to determine the number of clusters to be formed
- Clustering via Agglomerative Clustering
- Examining the clusters formed via scatter plot

Now that we have used the clustering method we can use those clusters as a new variable in our original Dataset :

Income vs spending plot shows the clusters pattern :
- group 0: high spending & average income
- group 1: high spending & high income
- group 2: low spending & average income
- group 3: low spending & low income